

Think about you’re an information analyst tasked with making a grasp gross sales dashboard, however as an alternative of beginning with a clear dataset, you inherit a Monthly_Logs folder filled with 50 CSV recordsdata overlaying completely different areas and months, a PDF containing transport price knowledge, and entry to a Supabase PostgreSQL database storing product prices. It’s important to flip all of that right into a single clear, normalized desk that you may really work with.
At first, it would seem to be the one option to deal with this type of mission is to manually copy and paste data throughout a number of recordsdata, however I discovered that wasn’t obligatory in any respect. Utilizing Energy Question, I imported knowledge from all three sources and merged all the pieces into one unified dataset in just some minutes. Alongside the best way, I eliminated junk rows, cut up columns, added customized columns, and cleaned inconsistent textual content formatting with out having to rebuild from scratch.
If you wish to comply with alongside, I’ve connected all of the recordsdata it’s essential attempt the method your self right here.
Associated
Excel lastly mounted its largest knowledge entry drawback, and it is a lifesaver
One click on within the Information tab can catch nearly all points.
Cleansing and consolidating CSV recordsdata
Utilizing Energy Question to mix, clear, cut up, unpivot, and standardize 50 CSV recordsdata without delay
On this case, the Monthly_Logs folder accommodates 50 separate CSV recordsdata, with one file for every area and month. Each file consists of three junk rows on the prime, 26 date columns unfold horizontally, a Store_Info column that really combines three completely different values into one area utilizing entries like 101-Chicago-60601, 15 pointless Internal_Notes columns, and product names that look as if they had been entered by completely different groups with completely different naming conventions.
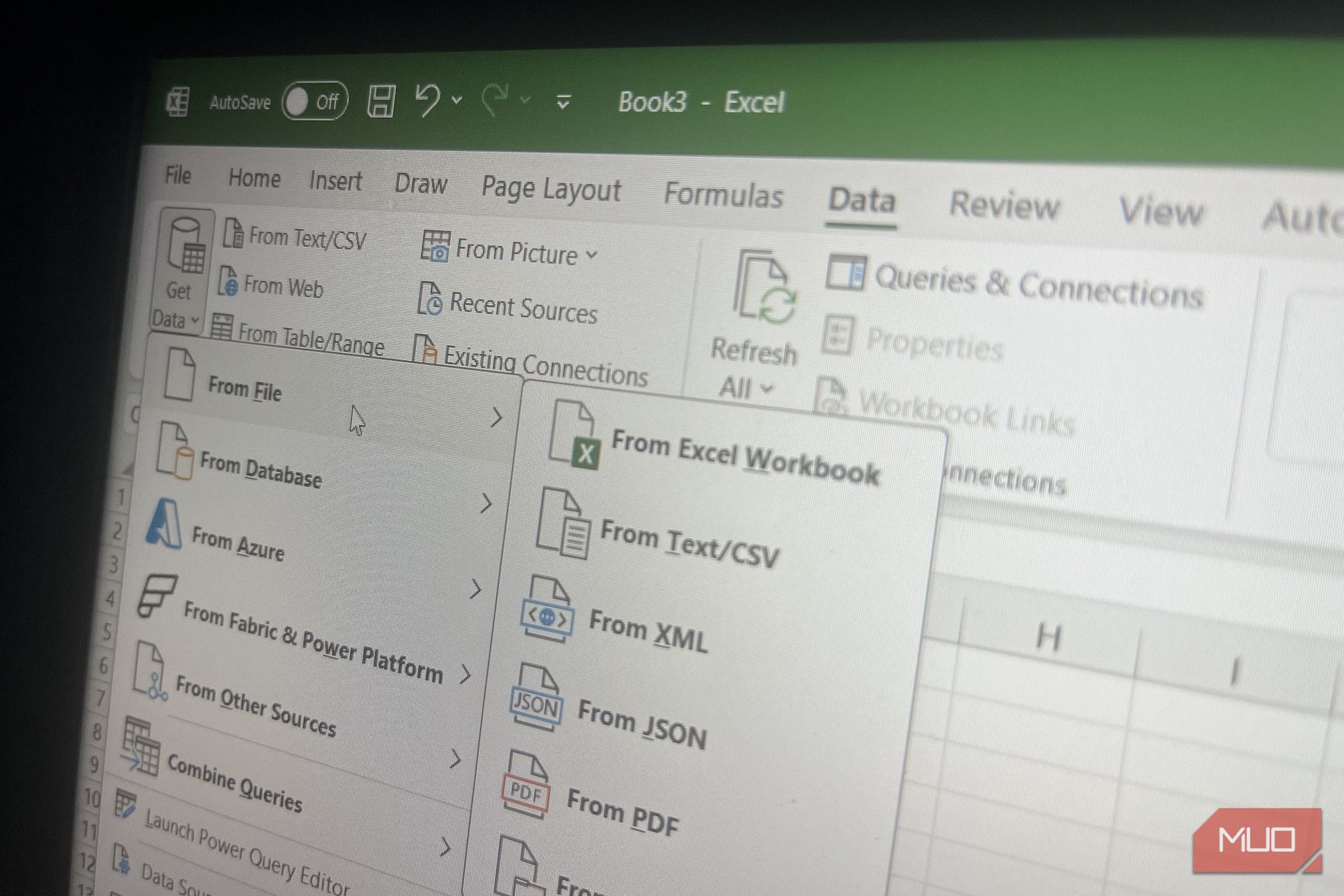
To begin organizing all the pieces, head to Information > Get Information -> From File -> From Folder in Excel, choose the Monthly_Logs folder, and click on OK. Within the preview dialog, select Rework Information, and Energy Question masses a desk the place every row represents a separate file. From there, click on the Mix Recordsdata button, which seems because the double-arrow icon within the Content material column. Energy Question instantly stacks all 50 CSV recordsdata right into a single desk.
As a result of each file begins with junk rows, although, you possibly can’t mix them with out cleansing them first. Within the Queries pane on the left, Energy Question mechanically creates a helper question referred to as Rework Pattern File. This question acts because the template for the way each CSV file shall be processed earlier than the merge occurs. Open it and apply your cleanup steps there by going to Residence -> Take away Rows -> Take away Prime Rows -> 3, then choose Residence -> Use First Row as Headers. As soon as you come back to the primary Monthly_Logs question, Energy Question mechanically applies those self same cleanup steps to all 50 CSV recordsdata earlier than combining them, which removes the junk rows throughout your complete dataset in a single go.
The following situation is the construction of the gross sales knowledge itself. Having 26 separate month columns with headers like Jan-2023 and Feb-2023 makes evaluation unnecessarily tough, particularly in case you plan to construct Pivot Tables or dashboards in Excel later. To normalize the info, maintain Ctrl and choose all 26 month columns, right-click, and select Unpivot Columns. Energy Question converts these huge columns into two a lot cleaner fields: one column containing the month title and one other containing the gross sales worth. You possibly can then rename the columns to one thing clearer, similar to Month and Sales_Amount.
The Store_Info column additionally wants consideration as a result of it combines a number of values right into a single area. Choose the column and go to Residence -> Cut up Column -> By Delimiter. Select the hyphen (–) delimiter and set it to separate at Every incidence. Energy Question immediately separates the sphere into particular person columns, which you’ll rename as Store_ID, Metropolis, and Zip.
At this level, the 15 Internal_Notes columns are simply litter. Maintain Ctrl whereas deciding on every pointless column, right-click, and select Take away Columns to clear them out of the dataset.
The Product_Name column additionally wants standardization as a result of inconsistent naming creates reporting issues. Begin by deciding on the column and going to Rework -> Format -> Trim to take away further areas earlier than or after product names. Then use Rework -> Format -> Capitalize Every Phrase to standardize the textual content casing. After that, use Residence -> Exchange Values to consolidate naming variations. For instance, you possibly can exchange “milk” with “Complete Milk” and “Milk-W” with “Complete Milk.” It’s additionally value checking for unintentional duplicates created throughout replacements, similar to “Complete Complete Milk,” so you possibly can clear these up as nicely.
To complete the cleanup course of, take away duplicate transactions by deciding on the Transaction_ID column, right-clicking, and selecting Take away Duplicates. Energy Question retains the primary incidence and removes repeated entries. Then filter the Amount column and uncheck null values to take away rows with lacking portions.
As a result of the ultimate mixed dataset is pretty giant, it’s higher to not load it instantly into a typical Excel worksheet. As an alternative, go to Residence -> Shut & Load -> Shut & Load To…, choose Solely Create Connection, and examine Add this knowledge to the Information Mannequin.
Screenshot by Ada
This pushes the dataset into Energy Pivot, which handles bigger datasets way more effectively and helps stop your workbook from slowing down or crashing.
Combining extra knowledge from in all places
Energy Question pulls all of it collectively, whether or not that’s databases, PDFs, or spreadsheets
With the CSV recordsdata cleaned and consolidated, the following step is pulling in the remainder of the info wanted for the grasp gross sales dashboard. On this case, which means importing product price knowledge from a Supabase PostgreSQL database and transport charges saved inside a PDF. Although these are utterly completely different knowledge sources, Energy Question handles each with out a lot hassle.
For the database connection, I discovered it best to attach Supabase by way of ODBC first after which import the info into Energy Question utilizing that connection by going to Information -> Get Information -> From Different Sources -> From ODBC, getting into your credentials, deciding on the product_cost desk within the Navigator window, and selecting Load To…. You may also set up the PostgreSQL driver and join instantly by way of Information -> Get Information -> From Database -> From PostgreSQL Database. Both means, simply load the info instantly into the Information Mannequin the identical means you dealt with the CSV dataset.
As soon as the product price desk is loaded, you possibly can merge it with the gross sales knowledge. Open the Monthly_Logs question and go to Residence -> Merge Queries. Choose Product_Name because the matching column out of your gross sales knowledge, select the product_cost question from the dropdown, and match it to the product_name column on the database aspect. Utilizing a Left Outer be part of retains each gross sales row whereas pulling in price knowledge wherever an identical product exists. After the merge finishes, click on the develop icon on the merged column and choose the fields you wish to import, similar to cost_per_unit, retail_price, gross_margin_pct, and SKU. Then use Shut & Load… to use the adjustments.
The PDF import works in an identical means. Go to Information -> Get Information -> From File -> From PDF, browse to Shipping_Costs_Invoice.pdf, and Energy Question mechanically scans the doc for tables. Within the Navigator pane, choose the desk containing the transport knowledge and cargo it into the Information Mannequin.
Earlier than you possibly can merge the transport data into the gross sales knowledge, although, each datasets want a shared column. The transport desk organizes charges by area, whereas the gross sales knowledge solely consists of metropolis names. To bridge that hole, create a brand new Area column contained in the Monthly_Logs question by going to Add Column -> Conditional Column. From there, construct guidelines similar to “if Metropolis equals Chicago, then Northeast,” repeating the method for each metropolis in your dataset and leaving a catch-all Else situation on the backside for something that doesn’t match.
Screenshot by Ada
In case your metropolis listing is giant, manually creating conditional guidelines will change into tedious. A extra environment friendly strategy is to construct a easy two-column lookup desk in Excel containing Metropolis and Area values. Convert the vary right into a named Excel desk with Ctrl + T, import it into Energy Question by way of Information -> From Desk/Vary, and cargo it into the Information Mannequin. From there, use Merge Queries inside Monthly_Logs to match the Metropolis column from each tables and pull within the corresponding Area mechanically.
With the Area column in place, merging the transport knowledge turns into easy. Go to Residence -> Merge Queries, choose the transport desk, match the Area column in each datasets, select a Left Outer be part of, and develop the fields you wish to embody, similar to Transport Zone, Service, Avg Weight, Charge/lb, Gasoline Surcharge, and Dealing with Price.
By the top of the method, you find yourself with a single, clear Information Mannequin containing all 50 months of stacked and unpivoted gross sales knowledge, correctly separated Store_ID, Metropolis, and Zip columns, standardized product names with duplicates and null values eliminated, product price and margin data pulled instantly from Supabase, and transport price knowledge extracted from the PDF. From there, constructing a dashboard turns into a lot easier as a result of all of the tough cleanup and consolidation work is already completed. All that’s left is to go to the Insert tab and choose PivotTable > From Information Mannequin.
Alternatively, you possibly can right-click the Monthly_Logs question, select Load To…, and insert the dataset right into a desk on any Excel worksheet you need.
You solely construct the workflow as soon as
Duties that used to eat a complete workday can now be arrange in just some minutes. The following time new CSV recordsdata arrive within the Monthly_Logs folder, all I’ll must do is go to Information -> Refresh All, and Energy Question will rerun each transformation mechanically. So long as the brand new recordsdata comply with the identical construction with matching headers and column counts, your complete cleanup course of occurs once more in seconds.
That’s finally why I feel Energy Question is among the most ignored instruments in Excel. It may possibly pull knowledge from nearly wherever, whether or not that’s an Excel spreadsheet or SQL server, deal with cleanup duties that will in any other case take hours manually, and course of datasets giant sufficient to overwhelm a standard worksheet. Extra importantly, it removes the necessity to repeat the identical cleanup work each time new knowledge reveals up, which is extraordinarily priceless.
OS
Home windows, macOS
Supported Desktop Browsers
All through net app
Developer(s)
Microsoft
Free trial
One month
Value mannequin
Subscription
iOS appropriate
Sure
Microsoft Excel is a strong spreadsheet utility used for knowledge group, evaluation, and visualization. It helps formulation, features, pivot tables, and charts to course of advanced datasets effectively. Extensively utilized in enterprise and schooling, Excel additionally integrates with different Microsoft 365 apps for collaboration, automation, and real-time knowledge insights.